
https://www.google.co.kr/books/edition/Recommender_Systems_Handbook/hGb_CgAAQBAJ?hl=ko&gbpv=1&dq=Recommender+Systems+Handbook.pdf&printsec=frontcover
Recommender Systems Handbook
Francesco Ricci is a professor of computer science at the Free University of Bozen-Bolzano, Italy. His current research interests include recommender systems, intelligent interfaces, mobile systems, machine learning, case-based reasoning, and the applicati
books.google.co.kr
줄임말 정리
- CF : collaborative filtering
- 협업 필터링
- 과거 행동이나 선호도를 바탕으로 유사한 사용자나 아이템을 찾아 추천을 제공
- RS : 추천 시스템
2장 - 추천시스템 데이터프로세싱 개요

데이터 전처리
- 거리 측정
- 샘플링
- 차원축소
- PCA
- SVC
데이터 분석
- 예측 - 분류
- KNN
- 의사결정나무
- Rules
- Bayesian Networks
- SVM
- ANN
- Description
- 연관규칙마이닝
- 군집분석
- k-means
- Density
- Message Passing
- Hierachical
해석
전처리
1. Similarity Measures
- 다음 방법으로 유사도 측정을 할 수 있음
- 유클리디안 거리
- 민코우스키 거리
- 마하라노비스 거리
- 코사인 유사도
- 피어슨 상관계수
- 자카드 계수
- Simple Matching coefficient (SMC)
2. 샘플링
- 8:2로 학습하고, 과적합이 발생할 수 있으니 n폴드 교차검증 필요
3. 차원축소
- 차원이 많아지면 오히려 성능 떨어질 수 있다
- 따라서 차원 축소가 필요함
- 다음 두 가지 방법으로 차원 축소를 할 수 있다.
- PCA (주성분 분석)
- SVD (특이값 분해)
3-1. 주성분 분석
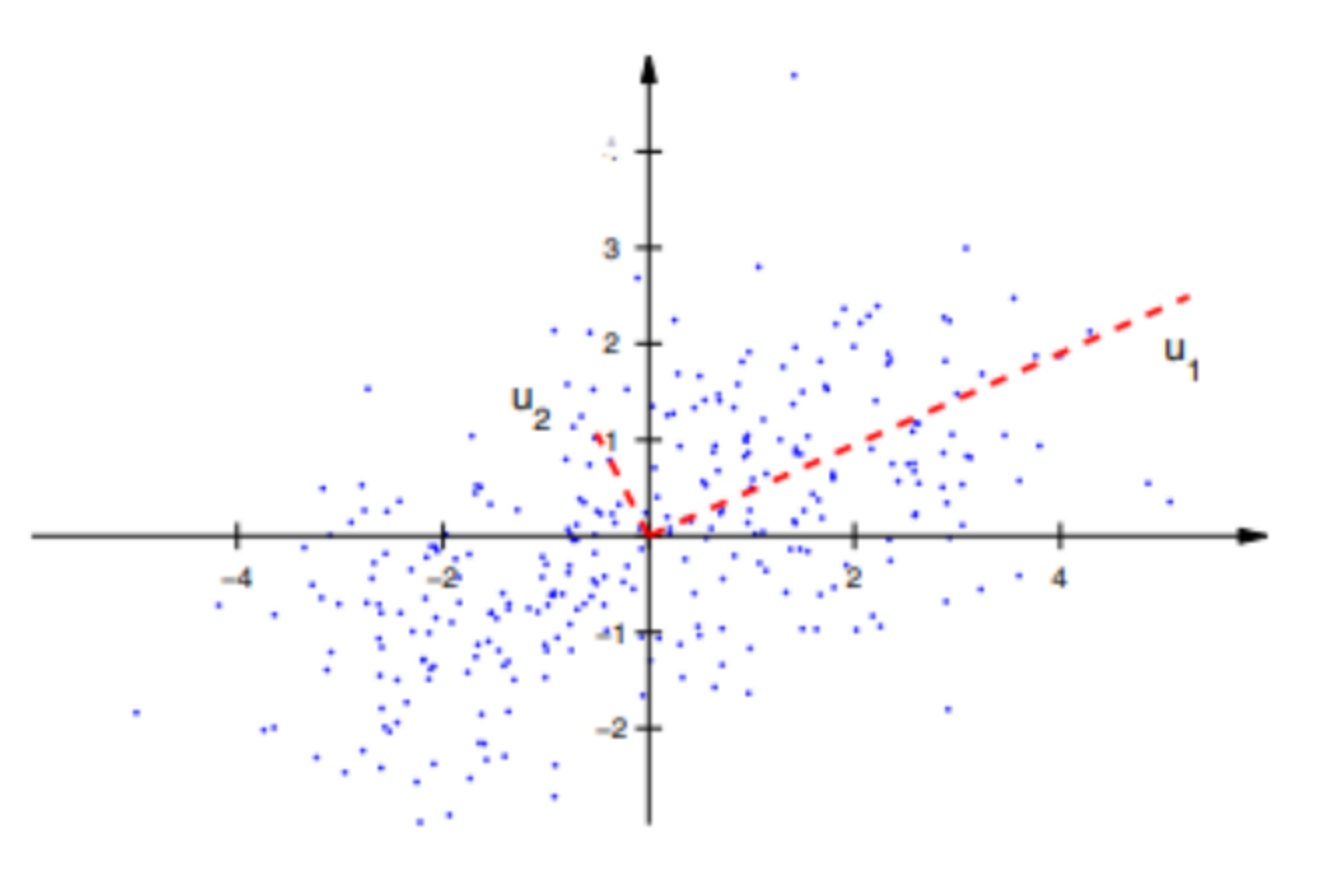
- 주성분 분석(Principal Component Analysis, PCA)은 가장 널리 사용되는 차원 축소 기법 중 하나로, 원 데이터의 분포를 최대한 보존하면서 고차원 공간의 데이터들을 저차원 공간으로 변환한다.
3-2. 특이값 분해
- SVD : Singular Value Decomposition
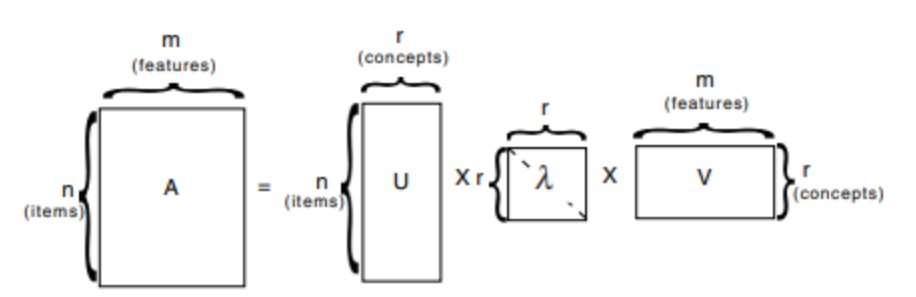
- 특잇값 분해(Singular Value Decomposition, SVD)는 행렬을 특정한 구조로 분해하는 방식으로, 신호 처리와 통계학 등의 분야에서 자주 사용된다. 특잇값 분해는 행렬의 스펙트럼 이론을 임의의 직사각행렬에 대해 일반화한 것으로 볼 수 있다.
- 행렬을 3개의 행렬로 쪼개 보는 것을 말함.
3-3. NNMF
- 기본적으로 SVD와 유사한 알고리즘
- 3개로 쪼개는 것이 아니라 2개로 쪼갬
4. Denoising
- 잡음 처리
데이터 분석 (분류)
1. Nearest Neighbors
- KNN
- 데이터로부터 거리가 가까운 'K'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로 거리를 측정할 때 유클리디안 거리 계산법을 사용
- k값이 너무 작으면 노이즈에 민감, k가 너무 크면 분류가 잘 안됨.
2. 의사결정나무
- 분류 속도 매우 빠름
- 추천시스템에 적합한 알고리즘임
3. Ruled-based Classifiers
- if ... then ...
- Ripper Algorithm https://www.geeksforgeeks.org/ripper-algorithm/
- CN2
4. Bayesian Classifiers
- BBN(Bayesian Belief Network)
- Bayesian Naive Classifier
- 조건부 확률을 사용 (사후 확률)
- 스팸메일 분류기에 유용
4-1. BBN vs Bayesian Naive Classifier
- BBN은 여러 변수간 복잡한 의존관계 모델링 가능, 유연함
- Bayesian Naive Classifier는 모든 입력 변수가 독립적이라고 가정함. 때문에 더 단순한 모델 구조를 가진다.
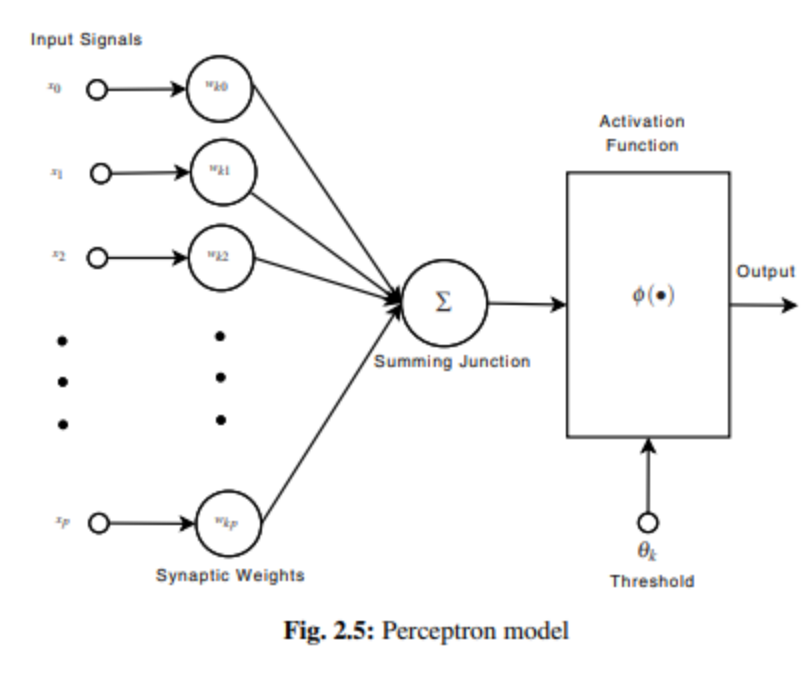
5. 인공신경망
- 퍼셉트론 모델
- 시그모이드, 임계함수, tanh 로 분류함.
- 다층 레이어 가질 수 있음
- 비선형 분류 작업 수행 가능
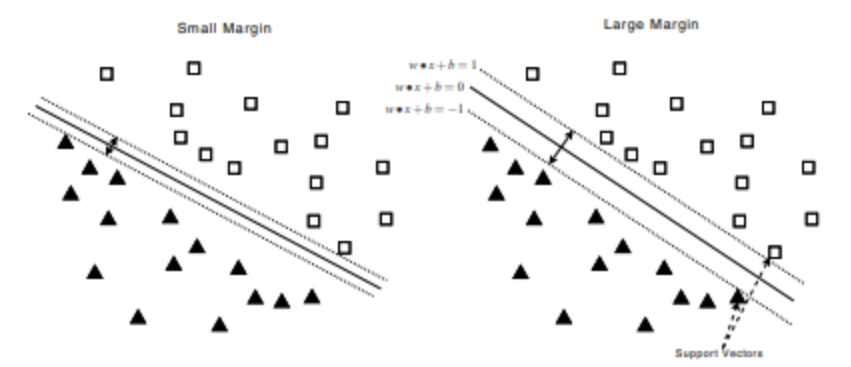
6. SVM
- 초평면으로 분류
- 이런 애들도 있다.
- SSVM(Smoothing Support Vector Machines)
- SSVMBH(SSVM-based heuristic)
- C-SVM : 상황 인식 벡터 머신
7. 앙상블
- 배깅, 아다부스트 등
- RankBoost 알고리즘 사용하여 영화 추천 생성.
분류기 평가
- 다음 방법으로 평가할 수 있음
- Mean Average Error
- Root Mean Squared Error
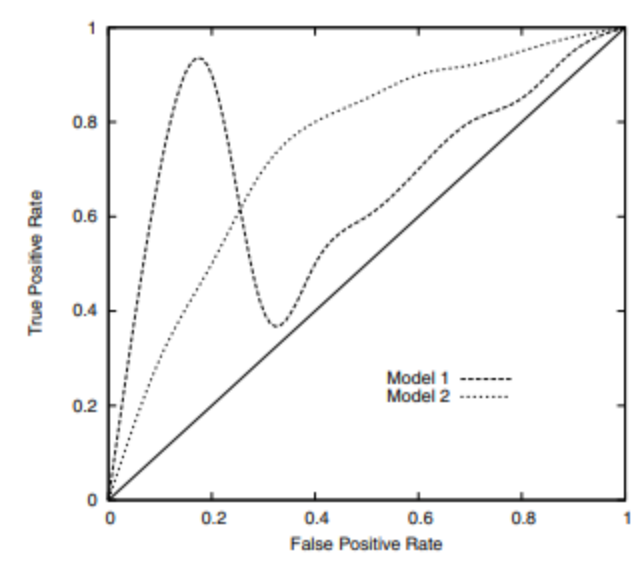
- 정밀도, 재현도 등을 사용해 평가 (ROC 곡선을 사용해 분류기를 평가함.)

군집 분석
- 비지도학습
- 다음 두가지 알고리즘을 사용한다.
- hierarchical 알고리즘 : 연속적으로 군집분석을 시행, 계층적 트리로 군집을 생성함.
- partitional 알고리즘 : 각 데이터 항목이 정확히 하나의 클러스터에 있도록 데이터 항목을 겹치지 않는 군집으로 분류함.
1. k-Means 군집분석
- 효율적인 군집분석 방법
- 단점 3가지
- 적절한 k를 선택해야함
- 초기 중심 선택에 매우 민감하게 성능이 좌우됨
- 빈 군집을 선택할 수도 있음.
2. Alternatives to k-means
- DBSCAN
- 밀도 기반 클러스터링 알고리즘
- k-평균과는 달리 클러스터의 모양과 개수를 미리 지정할 필요가 없음
- 밀도가 높은 지역을 클러스터로, 밀도가 낮은 지역을 노이즈로 처리
- Message-passing clustering
- 노드 간에 메시지를 주고 받는다.
- 계산 복잡함
- 복잡한 구조에도 강하다
- Hierarchical Clustering
- 가장 가까운 두 클러스터를 병합하면서 클러스터의 개수를 줄여 나간다.
- 계산 복잡성이 높다
연관규칙마이닝
- 지지도, 신뢰도, 향상도
'수업정리 > poject-study' 카테고리의 다른 글
| 화면설계도 (2) | 2023.10.27 |
|---|---|
| Apache Cassandra 튜토리얼 (0) | 2023.10.25 |

